-
R과 Data WranglingR 이모저모 2019. 8. 19. 23:04
오랜만에 써보게 되는 이번 글에서 다룰 주제는 R에서의 Data wrangling입니다. Data Wrangling은 '원자료(raw data)를 또다른 형태로 수작업으로 전환하거나 매핑하는 과정이다.'라고 정의되며, 흔히 분석 전의 전처리 과정에서 많이 마주하게 되는 문제들입니다. 예전 포스팅에서 다뤘던 dplyr 패키지가 R에서 보다 효율적인 데이터 처리를 할 수 있는 도구를 제공해주나, 이번에는 tidyr이라는 패키지까지 활용하여 보다 편하고 빠른 데이터 처리에 대한 팁들을 얘기해보고자 합니다.

1. Spread와 Gather
데이터 분석을 배우거나 관련 업무를 하는 많은 분들이 겪는 골칫거리 중 하나는 데이터를 n*m 데이터를 n' *m', 즉 다른 형태로 바꿔야 할 때 일 것입니다. 왠만한 작업의 경우 dplyr의 summarise가 이 역할을 잘 수행해주는 편이지만, 일일히 지정해주기 불편한 경우가 발생할 수도 있습니다. 예를 들어봅시다.

예제코드의 df 위 df 데이터는 3개의 칼럼(name, key, count)으로 구성되어 있습니다. 저는 이 데이터를 다음과 같이 key들의 값을 칼럼명으로 하고 count를 값으로 가지게 바꾸고 싶습니다.

당장 생각나는 방법은 name 변수로 group을 생성한 다음 칼럼을 하나하나 만드는 방법입니다. 이 방법은 코드가 지저분해질 뿐더러 key값의 레벨이 커질수록 비효율적으로 돌아가게 됩니다. 이처럼 6*3 데이터를 2*4 형식, 즉 길게 만드는 기능을 tidyr에서는 spread라는 함수로 제공을 합니다.

spread로 만든 결과 spread에서 key는 칼럼명이 될 변수명을, value는 해당 칼럼의 값이 될 변수를 의미합니다. 그래서 여기서는 key변수가 칼럼으로, count가 값으로 들어가며 나머지 변수인 name은 자동으로 그룹 역할을 하게 됩니다.
이처럼 spread가 유용한 역할을 하는것을 알게 되었습니다. 그럼 2*4데이터를 원래대로 돌리려면 어떻게 해야할까요? 이땐 spread의 반대, 즉 모아주는 gather 함수를 쓰게 됩니다.

gather 함수로 원래대로 돌아온 모습 spread와 다르게 gather에서는 key는 키값으로 모일 변수명을, value는 모인 값들의 변수명을 의미하며 뒷부분에는 무슨 칼럼을 선택하여 모으게 할지를 의미합니다. 위 예제의 경우 2~4번째 열인 A, B, C가 모여야 했으므로 2:4를 입력합니다.(혹은 변수명 A,B,C로 입력해도 가능합니다)
2. Separate와 Unite
다음은 separate와 unite입니다. 이 작업의 경우 mutate로 간단하게 할 수 있으나, 위 경우와 마찬가지로 변수를 많이 생성해야 할 필요가 있을때 요긴할 수 있습니다. 가장 대표적인 예는 날짜 데이터가 있습니다.
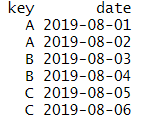
예제의 df2 날짜는 보통 공란 혹은 -로 구분이 되게 데이터가 들어오며, 이를 년/월/일로 나누는 작업이 필요할 수 있습니다. mutate와 substr로 직접 만드는 것도 한가지 방법이지만, 아래와 같이 separate를 이용하면 좀 더 쉽게 나눌 수 있습니다.

separate를 활용한 결과 처음은 나눌 변수명을, sep은 무엇을 기준으로 나눌지를, 마지막은 나눠진 변수들에 대한 변수명입니다. 위 date변수가 ymd로 깔끔히 나눠진 것을 확인할 수 있습니다.
위 spread - gather 관계와 마찬가지로, separate 또한 unite함수로 붙여줄 수 있습니다. 두 함수를 사용하며 기존 칼럼을 지우고 싶지 않다면 remove = F로 지정하는 것으로 방지할 수 있습니다.

unite로 다시 합친 결과 3. lead와 lag
순차적인, 주로 시간과 관련된 데이터를 다루다보면 직전 값이나 직후값을 가져와야할 경우가 많습니다. 이 때 변수[-1]해서 붙이는 등 수동으로 해주는 방법도 있지만 매우 번잡하며, group by 작업을 해야할 경우 더더욱 힘든 문제가 있습니다. 이 때 사용하는 함수가 lead와 lag로, lead는 직후값을, lag는 직전값을 가져오게 됩니다.(input 파라미터를 조정해서 더 앞/뒤의 값도 가져올 수 있습니다.)

랜덤으로 섞인 iris데이터에서 Species 변수의 lead,lag값 이 함수와 행 번호를 붙여주는 row_number를 활용하면 어느 시점에서 특정 변수가 바뀌는지 알 수 있습니다. iris 데이터의 Species가 변하는 부분을 아는 방법은 다음과 같습니다.

lead값이 바뀌는 부분이 50과 100 -> 51번째와 101번째는 다른 Species가 시작 
lag값으로도 같은 결과를 확인할 수 있음 주의할 점은 해당 함수는 데이터 정렬 순서에 따라 앞,뒤값을 표시하므로 시간 관련 데이터의 경우 정렬이 매우 중요하다는 것입니다.
4. dplyr::do와 rowwise Dataframe
다음으로 제가 최근 중요성을 느끼고 있는 nested dataframe입니다. do함수를 통해 생성하게 되는 이 tibble 객체는 더 빠른 서치나 복잡한 작업을 쉽게 해주는 역할을 해줍니다. 간단한 예를 들어봅시다.

df2 이전에 다뤘던 df2 객체에서, 저는 key값을 기준으로 2번째 date와 첫번째 date를 빼고 싶습니다. 물론 for문이나 수동으로 하는 방법도 쓸 수 있지만, do를 이용하면 다음과 같이 간단히 할 수 있습니다.

do로 생성된 객체 이제 rowwise(행 단위) 작업을 완료한 데이터가 생성되었습니다. diff 변수의 각 행은 리스트 형식으로 저장되어 있으며, 안에는 결과물이 들어가 있습니다. 이걸 다시 원본으로 돌리려면 tidyr의 unnest 함수를 활용해야 합니다.
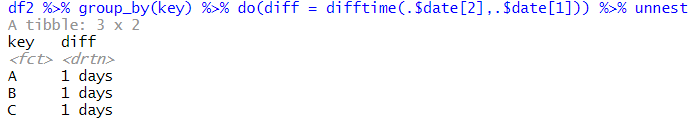
unnest된 데이터 신기하긴 하지만, 왜 이런 작업을 굳이 해야하는지 의구심이 들 수 있습니다. 이유는 크게 3가지 인데,
1. 키값으로 필터링을 할 때 시간을 줄일 수 있다.
2. 복잡한 작업을 한 결과물을 데이터프레임 형식으로 저장할 수 있다
3. 루프를 쓰지 않아도 되고, 조금 더 빠른 편이다
정도입니다. 글로만 보면 와닿지 않으니 좀 더 복잡한 예제를 들어보겠습니다.

예제 df3 다음과 같이 key값을 가지고, x,y 좌표를 가진 데이터프레임이 있을때 그룹별로 유클리디안 거리 행렬을 구하고 싶다고 합시다. 위 do 함수를 활용하면 다음과 같이 나오게 됩니다.

4개의 dist객체로 정리된 결과 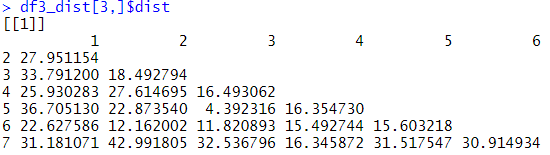
3번째 행의 distance 매트릭스 단점은, 위와 같은 경우 unnest로 풀기 어려운 형태기 때문에 unnest 함수로 강제로 풀어도 값이 보존되지 않는다는 점입니다. 대신 이렇게 그룹단위로 수행된 작업을 손쉽게 저장하고 꺼낼 수 있습니다.
특히 위 형식의 데이터는 큰 데이터를 키값 기준으로 서치해야할 때 빛을 발하는데, 이는 모든 행을 다 매칭해가면서 찾는것보다 줄어든 행에서 키를 찾고 그다음 펼치는 것이 유용하기 때문입니다. 예제에서는 1억 * 3의 데이터를 가지고 테스트를 해보았습니다.

일반 데이터프레임의 필터링과 묶인 데이터 필터링 후 unnest하는 과정 비교 보다시피 nested형식이 월등히 빠름을 알 수 있습니다. 물론 해당 형식의 데이터를 만드는 시간이 존재하기 때문에 무조건 우월하다고 볼 순 없지만, 어떤 작업을 처리하면서 동시에 키값을 찾는 속도를 향상시키려한다면 괜찮은 선택이 될 수 있습니다.
마치며
이번 글은 제목은 거창하게 지어놨는데 막상 쉽게 쓸 자신이 있는 소재가 한정되있어서 다소 맥락없이 써진 것 같습니다. 그냥 하나의 제목글마다 토막글이라 생각하고, R로 데이터 처리를 할 때 쓸만한 팁을 얻어가셨으면하는 바람입니다.
[컨텐츠 코드]
'R 이모저모' 카테고리의 다른 글
sf : R과 지도(2) (0) 2020.01.03 sf : R과 지도 (1) (0) 2019.12.06 웹 크롤링 기초와 R (0) 2019.07.21 R로 위키 빌보드 차트 가져오기 (0) 2019.06.23 ggplot2 : R 시각화 (1) 2019.06.10