-
웹 크롤링 기초와 RR 이모저모 2019. 7. 21. 23:23
이번 포스팅에서는 앞서 올렸던 위키피디아 데이터 가져오기를 어떻게 구현하는지에 대해 설명하고자 합니다. 웹 크롤링 자체는 해당 사이트의 구조가 어떻냐에 많이 의존하기 때문에 쉽게 배우기 어려우나, 위키피디아는 상대적으로 단순한 구조를 취하고 있기 때문에 이 글에서 다루는 것들은 R에서 웹사이트 정보를 어떻게 가져올까에 대한 워밍업 정도로 생각하시면 될 것 같습니다.
1. XML을 통해 html 구조 불러오기
이미 R에서의 크롤링에 대해 조금이라도 검색하신 분이라면 알겠지만, R은 해당 url의 html구조를 읽어 가져오는 형식으로 웹에서 정보를 수집합니다. 따라서 html구조를 읽고, R에 맞는 형식으로 맞추기 위해서는 그에 맞는 방법을 사용해야하며, XML,rvest 패키지가 해당 기능을 제공해줍니다.


XML과 rvest패키지 도구를 갖추고 난 후 크롤링을 효율적으로 하기 위해 확인해야 할 것은 원하는 사이트의 URL이 어떤 구조로 있느냐입니다. 하나의 사이트 페이지에서만 가져오는 경우에야 이러한 문제가 없지만, 여러 페이지를 뒤져야 하는 문제라면 url을 호출하기 위한 작업이 선행되어야하기 때문입니다. 이전 글에서 연습한 예제의 경우 위키피디아의 빌보드 HOT 100 연간 차트를 2015년부터 2018년까지 가져와야 했습니다. 다행히 위키피디아는 일관성 있는 url구조를 가지고 있기에 'http://en.wikipedia.org/wiki/Billboard_Year-End_Hot_100_singles_of' 뒤에 원하는 년도를 붙이는 것으로 해결되었습니다.

주소 뒤에 year객체를 붙여 원하는 페이지 url을 생성 url을 완성하면, read_html 함수를 사용해서 해당 주소를 읽어오게 됩니다.

2018년 빌보드 차트 핫 100 얼핏 보아하니 head와 body로 나누어진 xml 문서라는것 정도가 눈에 보이고, lang = 'en'은 언어 설정이 영어임을 의미함이 보입니다. 이제 이 객체에서 원하는 정보를 가져와야 하는데, 이때 크롬의 검사 기능이 유용하게 사용됩니다.
2. 웹 구조에서 html 노드 확인하기
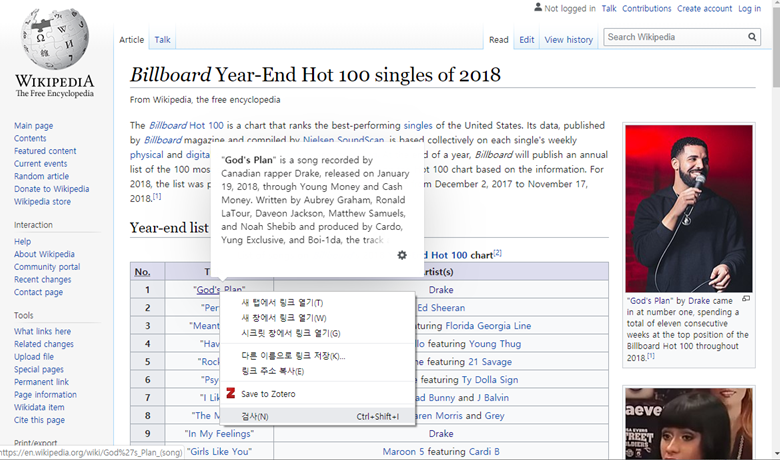
위 그림에서 보이다시피 크롬에서는 우클릭을 통해 검사 기능을 활성화 할 수 있습니다. 이 기능을 활용하면 아래와 같이 웹 사이트 구조를 볼 수 있는 창이 옆에 생성되게 됩니다.

지금은 굉장히 복잡해보이지만 구조 자체는 그리 어렵진 않으며 실제로 다 알 필요도 없습니다. 크롤링의 목적에 맞게 그저 원하는 정보가 어디에 담겨있는지만 확인하면 되니까요. 가장 간단환 확인법은 오른쪽의 창에 나와있는 코드들에 마우스를 갖다대서 확인하는 것입니다.
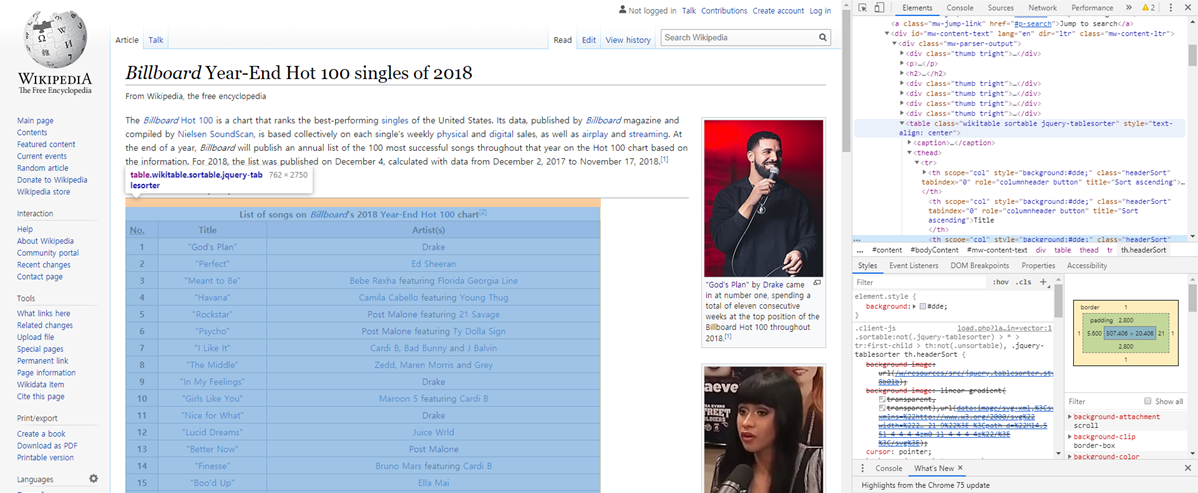
테이블 클래스 코드에 마우스를 올렸을때 모습 여기서 제가 원하는 정보인 곡 및 가수들의 테이블은 table.wikitable.sortable.jquery-tablesorter에 담겨있음을 알 수 있습니다. 이것을 R에 가져오기 위해서는 xml 문서의 해당 노드셋을 가져와야하며, 이는 html_node 혹은 html_nodes함수를 사용해서 가져옵니다.

가져온 테이블 노드셋 html_nodes함수는 불러온 xml문서를 첫 입력으로, xpath 표현식을 다음으로 받으며 표현식에 해당하는 모든 노드를 불러오게 됩니다. 위의 예시의 경우 표현에 해당하는 노드가 하나뿐이기에 하나만 나왔지만, 예를 들어 a라는 표현이 들어가는 노드를 호출할 경우 아래와 같은 결과가 나오게 됩니다.

따라서 원하는 정보가 어느 노드에 있는지 웹 구조상으로 확인하는것이 대단히 중요하며, 크롬의 검사 기능이 그 과정을 간단하게 해낼 수 있도록 도와주게 됩니다.
3. 노드셋 변환
이제 원하는 부분을 가져왔으니 다 끝난거 같지만, 원하는 부분은 xml표현들이 아닌 R에서 쓸 데이터들 자체기에 가공을 해주어야 합니다. html구조가 익숙하신 분은 직접 parsing을 하여도 되지만 보다 쉬운 방법으로 html_text와 html_table이 있습니다. 두 함수는 xml노드셋에 있는 정보들을 텍스트 혹은 테이블 형태로 빼오게 해주는 함수입니다.

문서 제목을 html_text함수로 가져온 결과 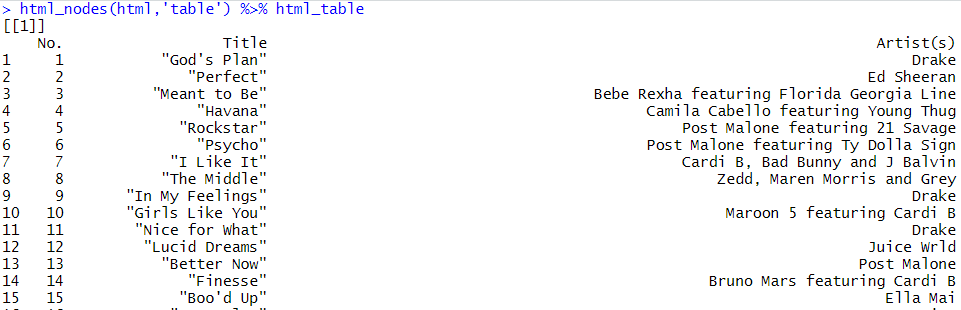
테이블 노드들을 데이터프레임 객체들로 바꾼 결과 주의할 점은 html_table의 경우 해당 노드가 형식에 맞아야 한다는 것입니다. 예를 들어 title 노드는 테이블을 이룰 정보를 가지고 있지 않기 때문에 html_table 함수에 통과시켜도 아무런 결과를 얻을 수 없습니다.
4. html 요소의 활용
이제 정보를 다 얻을 수 있고 R에서도 활용할 수 있게 되었습니다. 그래도 여전히 곤란한 부분이 있다면 아마 하이퍼링크를 통해 크롤링하는 것일 겁니다. 예를 들어 아까 본 위키의 테이블 두번째 줄에 에드시런에 걸려있는 하이퍼링크를 타고 들어가서 가수의 정보를 수집하고 싶다면 어떻게 해야할까요?

하이퍼링크를 크롤링하고 싶을때 html_attrs함수는 해당 노드가 어떤 요소를 가지고 있는지를 추출해주는 함수로, 하이퍼링크가 'a.href' 구조로 들어감을 이용해서 하이퍼링크에 대한 정보를 가져올 수 있습니다. 상기한 테이블을 html_nodes(html,'table.wiki.table.sortable')을 통해 노드셋을 가져온 상태에서, 다시한번 'a'라는 노드셋을 찾으면 아래와 같이 많은 정보들이 있는 것을 확인할 수 있습니다.

테이블 안의 'a'로 시작하는 노드들 밑에 출력값들을 보면, href로 하이퍼링크를, title로 웹 사이트 상에 나오는 글자들을 표시함을 알 수 있습니다. 이제 이 객체에 html_attrs를 적용하면 href와 title만 리스트로 정리되서 나오며, 이를 이용해서 해당 하이퍼링크의 정보를 가져올 수 있습니다.
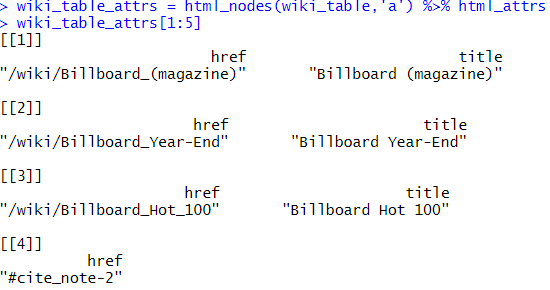
a노드들의 요소들 
하이퍼링크 문자들을 결합해서 read_html로 다시 읽어온 결과물들 5. 마치며
웹 크롤링은 데이터, 특히 소셜 데이터 쪽을 수집하기 위해 자주 사용되는 테크닉이나, 현재 봇 공격 및 정보 무단수집을 막기 위해 대다수 사이트들이 구조를 복잡하게 꼬아놓은 경우가 많습니다. 이를 해결하기 위해 보다 직접적으로 수집하는 셀레니움 등 다양한 방법이 나오고 있으며, 이를 공부하는 것이 상당히 유용할 수 있습니다. 하지만, 위의 예제처럼 간단한 구조나 오픈된 사이트에 대해서는 굳이 번거로운 방법 대신 써먹을 수 있는 xml기반 방법 또한 알아둘 가치가 있을 것입니다.
'R 이모저모' 카테고리의 다른 글
sf : R과 지도 (1) (0) 2019.12.06 R과 Data Wrangling (0) 2019.08.19 R로 위키 빌보드 차트 가져오기 (0) 2019.06.23 ggplot2 : R 시각화 (1) 2019.06.10 R과 네트워크 분석(2) (0) 2019.05.29