-
R과 병렬처리
R은 인터프리터 언어로 편리한 사용법 대신 속도 부분에서 한계가 많다고 지적을 받는 경우가 종종 있으며, 실제로 속도 때문에 불편함을 겪는 분들도 종종 있습니다. 하지만 정말 큰 데이터 처리가 아니라면 처리속도가 느린 대부분의 경우는 병렬처리가 되지 않거나 벡터/행렬 연산이 기반이 되지 않아 R에서 최적화된 연산을 하지 못해서 느린 경우가 많습니다.(간혹 비효율적인 패키지 사용시에도 발생합니다.) 그래서 오늘은 R에서의 병렬처리에 대해 간단히 다뤄보고자 합니다
1. apply 함수들
apply 함수는 엄밀히 말하면 병렬처리를 해주는 함수들은 아니지만(이는 apply에 적용하는 함수 function(x)에 print를 넣어보면 알 수 있습니다.), 후에 나올 foreach의 결과 산출 과정과 유사하고 별도의 오브젝트 할당 없이 쉽게 처리할 수 있는 방법이기에 맛보기로 다뤄보겠습니다. apply는 apply, sapply, lapply, mapply 등 다양한 종류가 있는데, 흔히 쓰는 것은 아마 sapply일 것입니다.

sapply 예시 : pkg라는 문자열에 require 적용 sapply는 첫 인풋 x의 요소(벡터 기준, 2차원일 경우 칼럼)마다 다음 인풋 FUN에서 정의한 함수를 적용한 결과를 제공합니다. sapply는 이름 그대로 simple한 apply로 함수가 적용된 결과를 matrix, vector, list 등 어떤 결과로 배출하는 것이 적합할지 자동으로 결정하여 보내줍니다. 덕분에 위의 패키지 로딩과 같은 간단한 작업을 진행할 때 편리하지만, 대신 형태를 결정하는 과정 때문에 속도가 느리다는 단점이 있습니다.
lapply는 list + apply로 위와 동일한 과정을 거치나 list형태로 고정해서 결과를 내보내는 함수입니다. 위 sapply와 동일한 과정을 거치면 다음과 같은 결과로 나옵니다.

lapply로 패키지를 로드한 결과물, list로 나옴 apply는 위 함수들의 원형이라고 할 수 있는 경우로, MARGIN이라는 인풋을 이용해서 1이면 row기준으로, 2면 column 기준으로, c(1,2)면 row와 column 기준으로 함수를 적용해 줍니다.

apply를 활용해 row들의 평균값(위)과 column들의 평균값(아래)를 구한 결과 purrr패키지에서는 map이라는 함수로 apply와 유사한 기능을 제공해줍니다.

map함수로 패키지를 로딩한 결과 위 함수들은 for(i in 1:100){...}와 같은 식으로 i를 할당하고 일일히 코드를 만드는 수고를 덜어주지만 위에 언급했듯 병렬처리는 해주지 않습니다. 이는 아래와 같이 print해주는 함수를 실행 시 순차적으로 결과가 나옴을 보면 알 수 있습니다.

1부터 10까지 print하는 sapply문 2. 병렬 처리 : foreach 와 for
이제 본격적으로 병렬처리에 대해 다뤄보겠습니다. R에서 여러 병렬 패키지들이 나오고 있지만 가장 일반적인 병렬 패키지는 foreach로, 이름 그대로 for문을 each 각각 돌려주는 기능을 합니다. 이 기능을 사용하기 위해선 R에 백엔드를 만들어줘야하는데요. 백엔드 생성을 위해서는 doParallel이라는 패키지를 사용합니다.
이제 백엔드를 몇개나 생성할지가 고민입니다. 스스로의 컴퓨터 cpu가 몇 코어 몇 쓰레드까지 할당 가능한지 알면 좋지만, 모르셔도 큰 문제는 없습니다. doParallel의 detectCores() 함수를 사용하면 현재 몇 쓰레드가 사용 가능한 지 알 수 있습니다. 이제 클러스터, 즉 병렬으로 일을 할 사람(백엔드)을 makeCluster함수를 이용하여 만드는데, 여기서 모든 코어를 다 할당해버리면 R외의 프로세스를 같이 켜놓기에 부담이 되므로, 적절한 수만큼 빼줍니다.

16개 쓰레드 중 1개를 제외한 15개를 생성한 결과 
makeCluster를 통해 생성된 15개의 백엔드 이렇게 백엔드를 설정해놓으니 병렬처리가 만능이고 모든 작업을 병렬로 진행하면 수월할 듯 하지만, 실제로는 그렇지 않습니다. 이유는 크게 두 가지인데 "1) 클러스터 할당에도 시간이 필요하다 2) 사공이 많으면 배가 산으로 간다" 입니다.
첫번째는 와닿지만 두번째 이유는 무슨 뜻인지 잘 와닿지 않을겁니다. 간단한 예제를 들어보겠습니다.
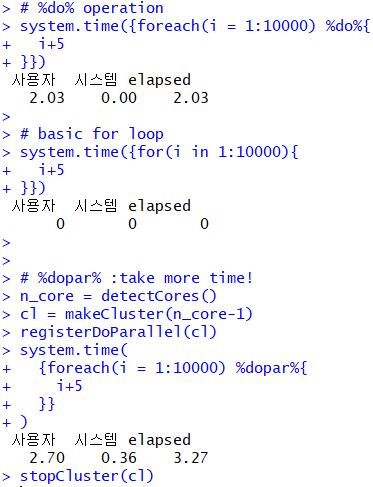
foreach의 %do%, for문, foreach %dopar% 결과 *%do%는 일반 for와 같은 동작을, %dopar%는 병렬처리를 진행합니다
여기 1부터 1만까지 i+5를 하는 루프 3가지를 실행해보았습니다. 당연히 병렬처리를 하는 foreach %dopar%이 가장 좋은 결과물을 보일 줄 알았으나, 놀랍게도 아무 패키지도 사용하지 않은 for문이 압도적으로 좋은 결과를 보입니다. 이 결과가 두번째 이유를 설명하는 예시인데, 각 클러스터 15개에게 i+5라는 작업을 할당하는 시간이 그냥 순차적으로 하는 것보다 오래 걸리기 때문입니다. 일상에서의 예를 들어보자면, 조별과제를 하는데 1부터 1000까지 받아쓰기를 하는 일을 4명이서 누가 어디서부터 어디까지 할지 정하고 하는 것보다 한명이 쓰는 것이 훨씬 빠른 경우입니다.

foreach %dopar%을 간단한 작업에 적용했을 때 3. foreach, 언제 써야할까?
그렇다면 foreach는 언제 써야 효율적일까요? 병렬처리가 빛을 발할때는 루프가 엄청나게 길거나 루프 안의 작업이 복잡할 때 입니다. 현재 앞의 문제는 R에서 basic 루프를 상당히 개선함으로서 for문 자체의 속도가 올라 양호한 편이며, 뒤의 문제는 여전히 병렬처리가 중요한 이유입니다. 예를 하나 들어보겠습니다.

iris 데이터에서 복원추출 200개를 한 데이터로 linear model을 만드는 과정 천 번 lm은 비교적 빠른 편인 함수이며 복원추출한 iris 데이터도 200개지만 이정도 작업에서도 foreach문이 for문보다 빠른 결과를 보여주고 있습니다. 물론 cluster 할당작업에서 걸린 시간을 치면 부족한 점은 사실이지만, 더 복잡한 작업을 많이 진행하게 된다면 유용할 것은 자명한 사실입니다.
여기서 중요한 사실은, 2번 파트에서 언급한 문제는 여전하다는 것입니다. 클러스터 15개의 작업은 기초 for문보다는 좋은 결과를 주지만, 작업에 비해 과분한 감이 있습니다.

6개의 쓰레드를 활용한 코드, 더 짧은 시간이 걸림을 확인할 수 있다 클러스터를 얼마나 만들지는 작업의 복잡도, 사용자의 컴퓨터 환경 등 여러 요소가 있어 어떤 것이 답이다라고 결정하기는 어렵지만, 위 예시에서 보다시피 과도한 클러스터는 여전히 독이 될 수 있음을 명심해야 합니다.
4. foreach 사용방법
이제 foreach를 어떻게 시작할지와 언제 사용해야 되는지는 어느 정도 감이 잡힐 것이라 생각됩니다. 이제 foreach를 어떻게 사용해야 제대로 된 결과를 얻을 수 있을지에 대해 말해보고자 합니다.
4-1 .combine
일반적으로 for문을 통해 객체값을 할당 할때는 빈 객체를 생성한 후 그 객체를 append, cbind, rbind 같은 함수로 확장하거나 a[i] 같은 식으로 인덱싱하여 순차적으로 할당하게 됩니다. 하지만 foreach문은 각각의 작업을 병렬로 처리하기 때문에 작업을 하며 순차적으로 할당하는 것이 불가능하며, 이 때문에 foreach는 작업이 종료된 후 결과물들을 하나로 합칠 함수를 직접 지정해줘야합니다. 이는 함수에 .combine이라는 인풋 옵션으로 표현되어 있습니다.

합칠 함수를 append와 rbind로 설정했을때 위의 그림에서 보다시피 append를 하면 벡터로, rbind를 하면 매트릭스 형식으로 결과를 내줌을 확인할 수 있습니다.
4-2 .packages
이제 foreach 결과물도 어떻게 내는지 알았으니 직접 돌려봅시다. 간단한 작업부터 복잡한 작업까지 다양한 시도를 하다가 아까 사용했던 예제 코드의 coefficient를 뽑기 위한 코드를 실행해보니 다음과 같은 오류가 발생합니다.

이는 foreach의 백엔드에는 글로벌 환경, 즉 우리가 보는 환경이 구성되있지 않기 때문입니다. 즉 %>%, sample_n 함수를 가지고 있는 dplyr 환경을 백엔드 안에서도 구성을 해줘야 정상적인 결과를 볼 수 있습니다. .packages는 어떤 함수를 쓸지 정해주는 옵션으로, 패키지 이름 문자열을 입력해주면 정상적으로 작동하는 것을 볼 수 있습니다.

정상적으로 출력된 coefficient matrix 4-3 환경 무게 줄이기
foreach는 기본적으로 글로벌 환경에 있는 객체들을 백엔드에 할당하여 작업을 진행합니다. 이 때 글로벌 환경에 있는 변수들 중 불필요한 것이 있다면, 이는 백엔드에 필요없는 부담을 주게 됩니다. 이를 해결하기 위해 .noexport 옵션을 활용할 수 있습니다. .noexport는 원하지 않는 객체의 이름을 넣으면 해당 객체를 제외하고 백엔드로 가져오는 역할을 합니다.

a를 1로 정의하고 export를 안할 경우, 기본환경의 iris는 찾으나 a라는 지정 객체는 찾지 못하는걸 볼 수 있다 5. foreach 그만 사용하기
이제 foreach와 관련된 작업을 끝냈으니 사용했던 프로세스를 차지하고 있는 백엔드들을 삭제하고 싶습니다. 이때 아까 만들었던 cl이란 오브젝트를 stopCluster함수의 인풋으로 넣으면 백엔드가 사라지는 것을 확인할 수 있습니다.

기본상태로 돌아온 Rstudio 6. 다른 병렬 기능들과 첨언
foreach말고도 앞서 소개한 lapply를 병렬처리로 해주는 parallel 패키지의 parLapply, 멀티 코어 apply 함수인 mcapply 등 여러 병렬처리기법이 담긴 패키지들이 R에 등록되고 있습니다. foreach와 doParallel이 제일 무난하고 이해하기 쉬운 패키지이나, 보다 더 나은 코드 성능을 위해서 다른 병렬패키지를 연구해 보는 것도 좋을 듯 합니다.
더불어서, Hadley Wickham의 Advanced R 책에서도 설명하듯 R은 벡터, 행렬 연산 등 R에 맞는 최적화된 환경을 구성했을 때 좋은 성능을 보장합니다. 루프 처리를 보다 빠르게 처리해주는 병렬처리 기능도 좋지만 루프를 사용하지 않고 할 수 있는 다른 방법이 있지 않을까를 고민해보는 것도 좋은 시도일 것 같습니다.
[컨텐츠 코드]
'R 이모저모' 카테고리의 다른 글
R과 워드 (0) 2019.04.19 R과 대시보드 : Shiny (0) 2019.04.09 알고리즘 소개 : XGBoost (0) 2019.03.30 R과 데이터프레임(3) (0) 2019.03.24 각양각색의 R 질문들과 풀이 (0) 2019.03.21