-
R과 워드
지금까지 포스팅은 비교적 많이 알려진 소재들을 다뤘었는데요, 이번에는 좀 색다른 주제를 다뤄보고자 합니다. 바로 워드에 있는 데이터를 R을 활용하여 가져오는 것입니다. 단순히 텍스트를 가져오는 것 뿐만 아니라 스타일, 테이블 등 다양한 객체를 가져오려면 R에서 워드 구조를 읽을 수 있는 방법을 알아야 하며, 동시에 XML구조 또한 알고 있어야합니다.

다양한 스타일을 포함한 워드 파일 1. 워드와 XML, 그리고 R
워드를 R에서 효과적으로 읽으려면 XML구조를 기반으로 읽어야합니다. XML는 데이터를 기술하는데 특화된 언어로, 미리 짜여진 구조를 이용하여 보다 효과적으로 데이터를 읽는데 큰 도움을 주게 됩니다. R에서 xml을 읽기 위해서 아마 웹크롤링을 위해 많이 봤을 패키지인 XML패키지를 사용합니다. 이 패키지는 xml문법에서 사용하는 표현들을 xpath 표현들로 읽어 원하는 부분을 찾을 수 있도록 도와줍니다.
워드의 XML구조는 매우 다양하지만, 이번 포스팅에서는 3가지 표현을 주로 사용할 것입니다. 먼저 단락(paragraph), 즉 엔터를 쳐서 바꾸기 전까지 쓴 줄은 워드에서 w:p로 표현됩니다. 다음 볼드체는 bold의 b를 따서 w:b, 기울임체는 italic의 i를 따서 w:i로 표현됩니다. 보통 워드는 단락을 한 단위로 스타일 등 정보를 저장하게 되며, 이를 이용하여 워드 데이터를 가져오는 예제를 해보겠습니다.
2. docxtractr 패키지와 XML을 활용한 스타일 읽기
XML패키지들이 워드 파일을 읽기 위해서는 먼저 워드 파일을 xml구조의 파일로 읽어와야합니다. 이를 위해서 워드파일 unzip 및 읽어오기 기능을 위해 docxtractr패키지를 사용합니다. 패키지의 read_docx함수를 이용하면 다음과 같이 결과가 나오게 됩니다. (예제파일 형태에 관해선 첨부된 워드파일을 참고해주세요)
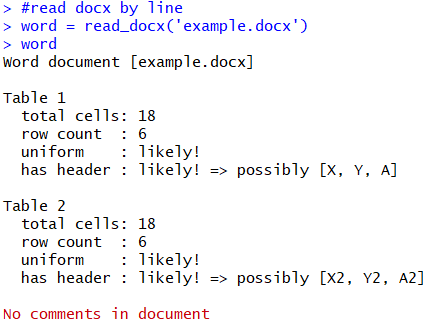
read_docx로 읽어온 파일 형태 문제는 docxtractr 패키지는 기본적으로 워드 테이블을 읽기 위해 설계되었기에, 해당 객체를 콘솔에 print하면 테이블에 대한 정보만 보여준다는 것입니다. 여기서 xml document형식의 데이터를 불러오려면 word라는 리스트에서 docx라는 요소를 가져와야합니다.
xml document 객체 2.1 parsing과 텍스트(w:t), 단락(w:p)
하지만 현재 word$docx라는 객체는 나눠지지않은 통짜 xml데이터로, 이 데이터에서 구조를 읽어내려면 손수 루프를 돌려서 찾아내야하기에 매우 비효율적입니다. 따라서 xml 문법에 맞게 나누는(parsing) 작업이 필요하며, 이 작업을 위해 xmlParse 함수를 사용합니다.

나눠진 xml document 이렇게 나눠진 문서는 콘솔에 표시되게 할 시, 위의 객체에 비해 깔끔하게 정리된 모습을 볼 수 있습니다. 이제 이 구조에 xpath 문법을 활용하여 문자를 찾아보겠습니다. 워드에서 텍스트는 w:t로 표현되며, xpath에선 //w:t로 표현된 노드를 검색함으로서 찾을 수 있습니다.

w:t를 포함한 노드들의 집합(nodeset) 하지만 이렇게 찾은 nodeset들은 의미를 찾기가 힘드므로, xmlValue함수를 이용하여 일반적인 문자열 객체로 변환할 수 있습니다. 이때는 저번 포스팅에서 다뤘던 sapply의 xpath버전인 xpathSApply를 사용합니다.

xmlValue를 사용하여 결합한 문자열 하지만 일부 문자열들, 예를들어 231이라고 표현한 글자들이 2,3,1과 같이 떨어져있는 경우를 볼 수 있습니다. 이것을 방지하기 위해서 줄바꿈 단위로 노드를 찾아볼 필요가 있으며, 워드에서는 w:p로 표현하게 됩니다.

단락별로 정리된 문자열들 2.2 단락별로 워드 글자 스타일 찾기
하지만 위와 같이 단순한 문자열만 검색하려면 textreadr의 read_docx함수를 사용하면 보다 간편하게 할 수 있습니다. 이번 포스팅에서 다루려는 주제는 위의 기능을 넘어서, 단락이 어떤 스타일을 가지고 있는지까지 확인할 수 있는 것입니다. 예를 들어, 볼드체는 워드에 w:b로 저장되는데 그냥 getNodeSet이나 xpathSApply에 //w:p//w:b를 하게되면 높은 확률로 텍스트를 가지지 않은 부분만 가져오게됩니다.
이를 방지하기 위해 매 단락(w:p)과 단락의 끝(/w:p) 사이에 해당 표현이 있는지 확인해주는것이 필요하며, 문제는 xml에는 R의 일반 문자열처럼 grep을 통해 확인할 수 없다는 것이며, 이를 위해 saveXML로 해당 노드의 표현식을 문자열로 가져오게 합니다. 그리고 이렇게 가져온 문자열에 볼드 표현인 <w:b/>가 존재하면 볼드체로 인식하게 하며, 기울임체 표현인 <w:i/>가 있으면 기울임체로 여기게 됩니다. 이 과정을 코드로 정리하면 아래와 같이 됩니다.

단락 단위로 표현을 읽은 후 스타일 별 탐색 
결과 다른 표현들도 위와 비슷한 방식으로 찾아낼 수 있습니다.
3. docxtractr 패키지와 테이블 읽기
다음으로 살펴볼 것은 워드에 있는 테이블을 읽는 것입니다. 워드에서는 테이블을 w:tbl형식으로 저장하며 테이블의 행은 w:tr(table row), 열은 w:tc(table column)으로 정리합니다. 이를 위와 같은 방식으로 일일히 찾아서 정리할 수도 있지만, docxtractr이 본래 워드 테이블 및 코멘트를 다루기 위한 패키지인 만큼 함수를 활용하여 간단히 정리할 수 있습니다. 위에서 read_docx를 이용하여 읽은 객체를 docx_extract_all_tbls를 사용하면 각 요소마다 테이블을 데이터프레임을 가진 리스트 형식의 객체를 반환하게 됩니다.

docx_extract_all_tbls를 사용한 결과 이 함수는 기본적으로 header, 즉 칼럼 이름을 예측해서 지정해주게 되있으나, 만약 그 기능이 필요하지 않다면 guess_header=F 옵션을 넣어주면 됩니다. 만약 함수가 적절한 header가 없다고 생각하면 자동으로 칼럼 이름이 없이 나옵니다.

guess_header = F를 적용한 결과 4. 마치며
사실 워드 데이터는 분석 업무간 그렇게 자주 볼 수 있는 경우는 아닙니다. 그래서 대부분의 사람들이 소흘하게 여기게 되고, 저 또한 막상 워드 데이터에서 정보를 가져와야 할 때 매우 곤란한 적이 있었습니다. 비록 그 때는 문자열로 표현을 가져온 후 모든 표현을 다 확인하는 무식한 방법으로 코딩했었지만. 이번 글을 쓰면서 다른 방법을 정리해서 찾을 수 있는 좋은 기회를 가졌던 것 같습니다.
[컨텐츠 코드]
'R 이모저모' 카테고리의 다른 글
R과 네트워크 분석 (1) (0) 2019.05.12 Shiny : 대시보드 배포하기 (7) 2019.04.24 R과 대시보드 : Shiny (0) 2019.04.09 R과 병렬처리 (4) 2019.04.03 알고리즘 소개 : XGBoost (0) 2019.03.30